产品概述
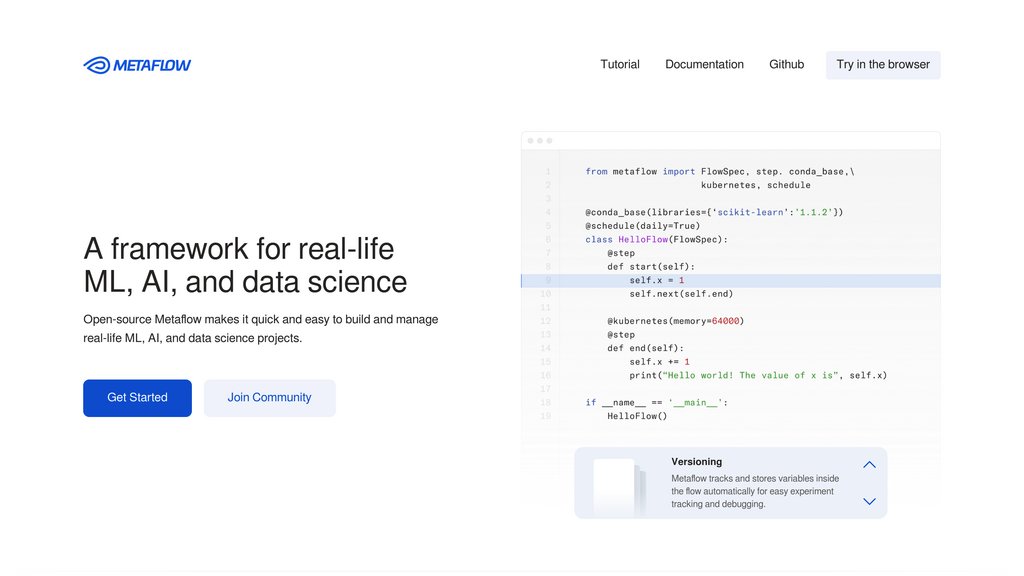
Metaflow是一个最初由Netflix开发的开源Python库,旨在简化数据密集型应用程序(包括机器学习和数据科学项目)的开发生命周期。它提供了一个直观的API,用于将工作流定义为Python代码,无缝处理数据版本控制、实验跟踪和可扩展计算编排。Metaflow支持本地开发并平稳过渡到云或本地Kubernetes环境,使团队能够快速构建原型并以最小的开销部署生产级工作流。其设计与现有基础设施和主要云提供商良好集成,使其成为管理复杂、真实世界数据工作流的可靠选择。
主要功能
| Python化工作流编排 | 使用简单的Python装饰器定义复杂的多步骤工作流,支持分支和合并,便于本地开发和调试。 |
| 自动版本控制和检查点 | 在每个步骤自动跟踪和存储所有数据制品和变量,实现可重现性、实验跟踪和故障恢复。 |
| 可扩展计算集成 | 利用Kubernetes、AWS Batch等平台,使用CPU、GPU和多个实例并行,无缝扩展工作流到云环境。 |
| 数据访问和管理 | 促进工作流内的数据流畅通,并提供从数据仓库和湖泊访问数据的模式,确保高效的数据处理。 |
| 生产部署和响应式编排 | 通过单个命令将工作流部署到生产环境,并支持事件驱动触发器实现动态工作流执行。 |
| 协作和基础设施友好 | 与现有安全、治理和基础设施策略良好集成,支持各种规模的团队并促进协作。 |
使用场景
- 快速原型设计和实验:数据科学家可以在扩展前在本地快速构建、测试和迭代机器学习模型和数据工作流。
- 大规模数据处理:通过在云资源和多个计算节点上并行化任务,高效处理海量数据集。
- 协作数据科学项目:团队可以共享版本化的数据、代码和结果,以保持一致性并加速项目开发。
- 机器学习工作流产品化:在生产环境中部署、监控和维护强大的机器学习管道,只需最少的代码修改。
- 实验跟踪和可重现性:自动跟踪实验和数据版本,确保结果可重现并简化调试。