
产品概述
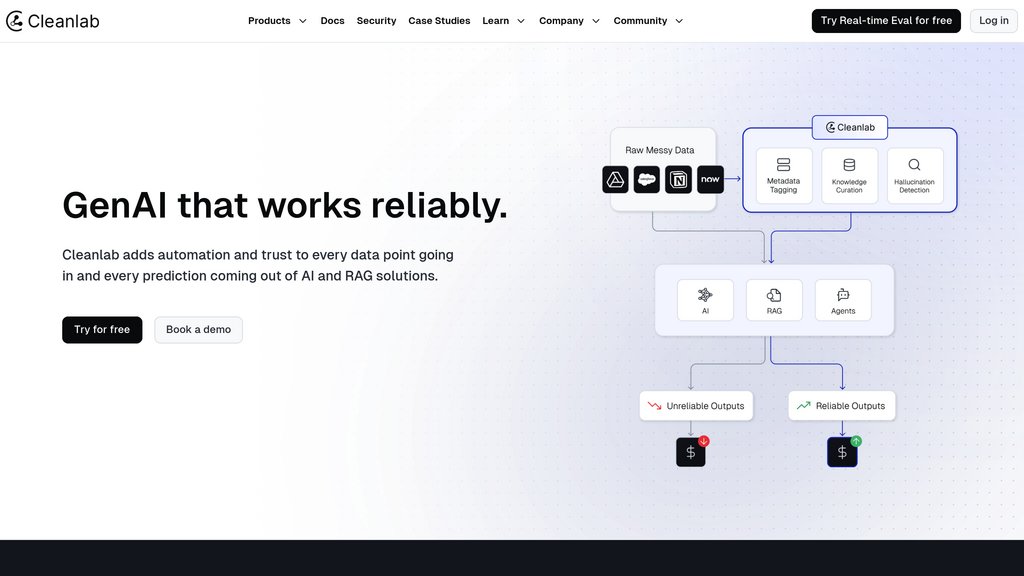
Cleanlab提供无代码、数据不可知的解决方案,通过自动识别标签错误、异常值、重复项和其他数据问题来提高数据集质量。它支持广泛的数据类型,包括表格、文本、图像、视频和音频。Cleanlab Studio简化了从数据清洗和标注到模型训练和部署的整个机器学习工作流程,使用户能够快速将原始、嘈杂的数据转变为准确、可部署的机器学习模型。凭借强大的安全功能和可扩展性,Cleanlab适用于处理敏感数据和大型数据集的企业。
主要功能
| 自动化数据问题检测 | 利用先进算法识别各种数据类型中的标签错误、异常值、重复项和数据漂移,无需手动设置规则。 |
| 无代码数据清洗和标注 | 提供直观的界面用于纠正数据问题和自动标注大型数据集,减少人工工作并加速数据集整理。 |
| 端到端机器学习工作流集成 | 支持在单一平台内从数据清洗到模型训练、调优和部署的无缝过渡,实现可靠模型的快速部署。 |
| 广泛的数据和模型兼容性 | 适用于结构化和非结构化数据,并与任何机器学习框架或模型集成,包括PyTorch、TensorFlow、HuggingFace等。 |
| 企业级安全 | 提供行业标准安全性和虚拟私有云部署选项,保护敏感数据并保持合规。 |
| 可扩展性和灵活性 | 处理各种大小和类型的数据集,适应不断增长的数据需求,同时不影响性能。 |
使用场景
- 数据质量保证:自动检测和修复数据集中的错误,提高机器学习模型的准确性和可靠性。
- 自动化数据标注:快速为大型数据集生成高质量标签,实现更快的监督学习模型开发。
- 模型部署和监控:直接从平台部署训练好的模型,并实时监控数据质量和模型性能。
- 行业特定应用:提升金融、医疗、制造和法律等行业的数据可靠性,用于欺诈检测、患者护理、质量控制和文档分析。
- 主动学习和标注管理:优先处理需要标注或重新标注的数据样本,优化标注工作并提高模型训练效率。




