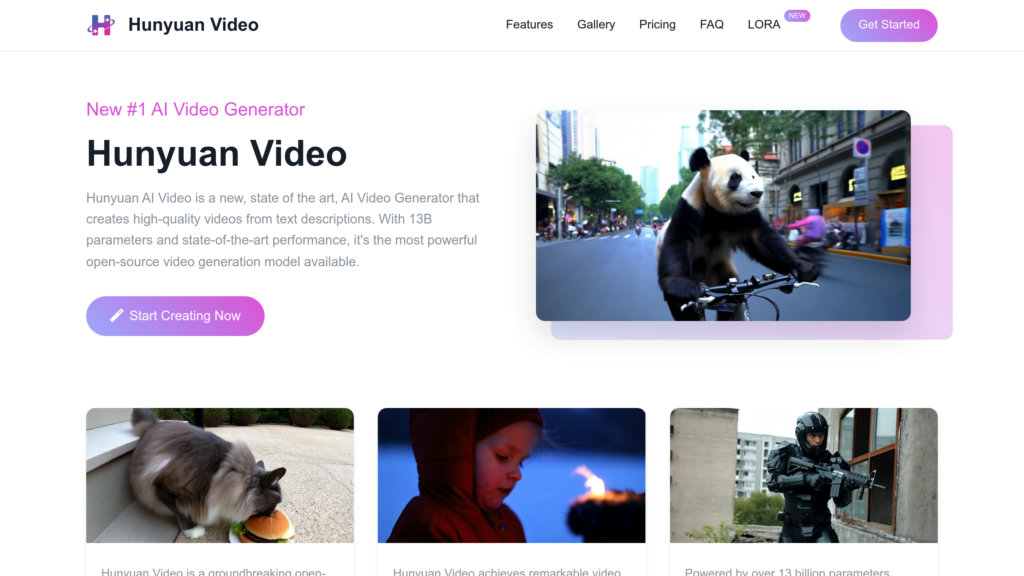
产品概述
Hunyuan Video 是腾讯推出的前沿AI文本生成视频模型,拥有130亿参数。可将文本描述转化为高分辨率、真实感强、运动流畅、语义丰富的视频。采用创新的双流合一架构与强大的多模态大语言模型(MLLM),实现文本与画面的精准对齐。系统集成高效3D VAE压缩,保障视频质量同时优化资源占用。开源特性促进社区创新与广泛应用,是专业级AI视频创作的领先方案。
主要功能
| 双流合一架构 | 分别处理视频和文本数据后再融合,提升模型对输入文本与生成视频内容的理解与一致性。 |
| 多模态大语言模型(MLLM) | 先进的文本编码器,在文本-图像对齐、细节识别和零样本学习方面超越传统模型,确保用户指令被精准理解。 |
| 高效3D VAE压缩 | 采用基于CausalConv3D的压缩技术,在保持原始帧率和高分辨率的同时,大幅降低计算资源消耗。 |
| 高分辨率电影级输出 | 可生成最高1280x720p、24帧每秒的流畅视频,画质专业,适用于多种创意场景。 |
| 可定制提示词模式 | 提供Normal与Master两种提示词模式,用户可按需在语义准确与视觉效果增强之间灵活选择。 |
| 开源与社区驱动 | 已在GitHub开源,鼓励创新,开发者可根据不同需求扩展和定制模型。 |
使用场景
- 内容创作:帮助创作者通过简单文本指令,快速高效地生成营销视频、宣传片和社交媒体短片。
- 广告与品牌宣传:支持企业生成高质量产品演示和品牌故事视频,风格与场景可精准把控。
- 教育与培训:将文字讲解转化为动态视频内容,便于制作生动的教学视频和培训教程。
- 艺术与创意项目:支持艺术家和动画师探索独特的视频风格和特效,包括图像转视频与角色一致性动画。
- 社交媒体与短视频:专为生成适用于抖音、快手、B站等平台的高清短视频优化。